
If you read the second part of the introduction to neural networks you know that gradient descent has a disadvantage when we want to train large datasets because it needs to use all the dataset to calculate the gradient.
Also as you can see we have specifically chosen a convex cost function. In essence, this only has one minimum and it is the global minima.
But what if our function is not convex. Well, first of all, it can happen if we choose a cost function which does not have a convex function or it can happen in a multidimensional space it can actually turn into something that is not convex.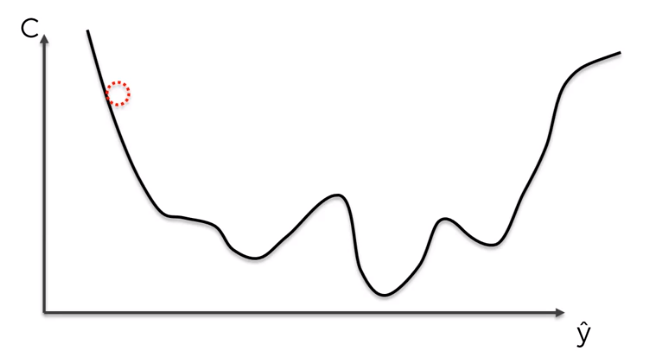
And if we try to use gradient descent to find the global minima we can get stuck in local minima of the cost function rather than the global minima.
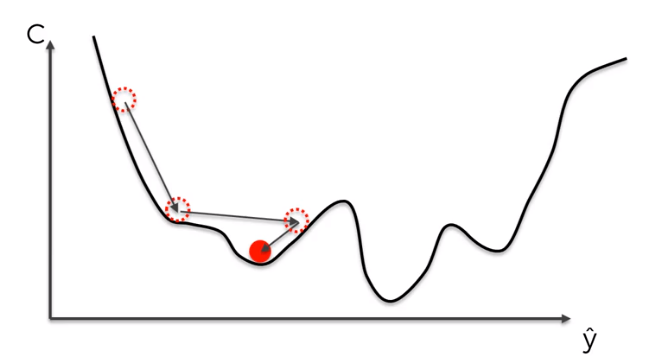
To solve this problem we use Stochastic Gradient Descent which does not require the cost function to be convex.
In both gradient descent (GD) and stochastic gradient descent (SGD), you update a set of parameters in an iterative manner to minimize an error function.
